
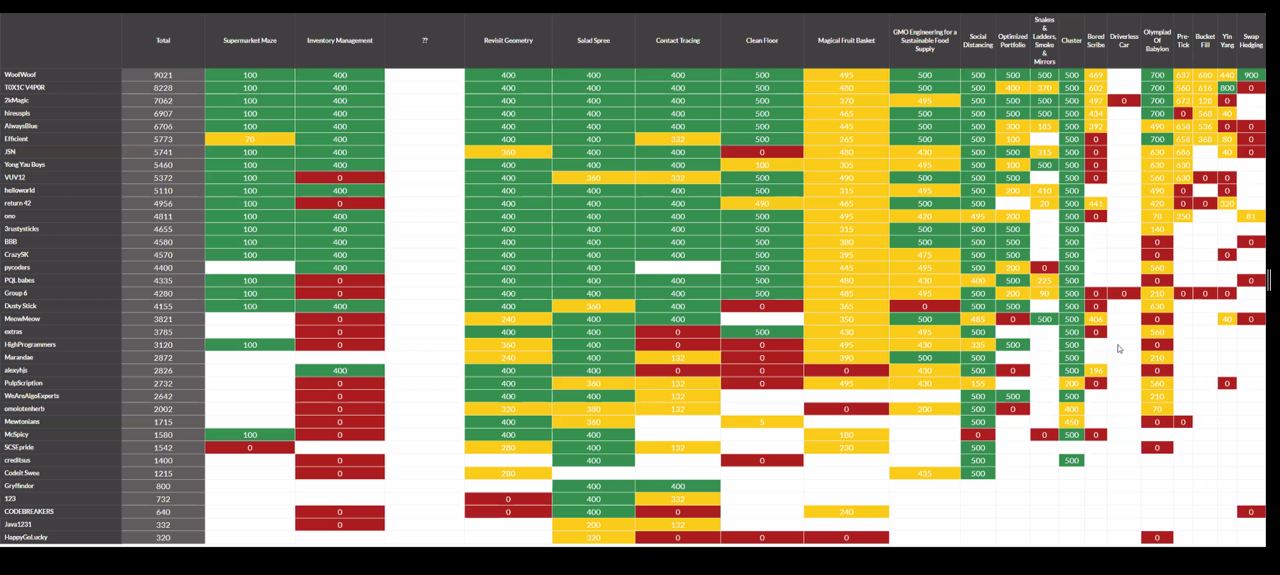
Sim Zhi Qi
Renaissance Engineering Programme (REP) is a dual-degree programme characterised by the awarding of a Bachelor of Engineering Science coupled with a Master of Science in Technology Management. Concurrent with the program is also a 1 year exchange to the University of California, Berkeley.
Specialising in Computer Science, my interests include backend web development and system architecture design. I am passionate about technology and have been actively seeking to expand my knowledge in the field of software engineering.
My hobbies include travelling and photography. I love to explore new places and experience new cultures. I have travelled to more than 30 countries and am looking forward to explore more countries in the future.
Enterprise Engineering Intern
May 2021 - Aug 2021
Software Engineering Intern
Aug 2020 - Jan 2021
Software Engineering Intern
May 2020 - Aug 2020
Software Engineering Intern
May 2019 - Aug 2019

Renaissance Capstone Project

Personal Project

CZ4034 - Information Retrieval Project

Singapore Airlines AppChallenge 2018
CZ4153 - Blockchain Project (Decentralized Application)
CodeIT Suisse 2020

Shoppe National Data Sceience Challenge 2019

NISTH Ideas Challenge 2019
Personal Project
Personal Project

CZ2006 - Software Engineering Project

Toshiba Retail Challenge 2018

HacknRoll 2019
Personal Project
Enterprise Engineer Intern

Software Engineer Intern

Software Engineer Intern

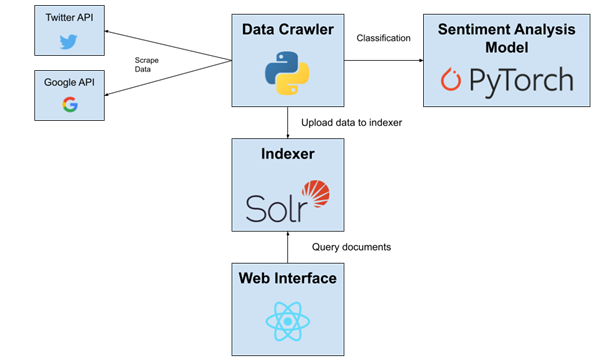
This was an entry task for all new hires within the WSA team to allow us to familiarize ourselves with the team's tech stack. I was tasked to design and develop a micro-service application that would be able to track prices of any item in the Shopee's e-commerce platform. The task started with a design of the whole application which I have decided to split each service up to specific services based on the functionality requirements and finalize my design to be as shown below.
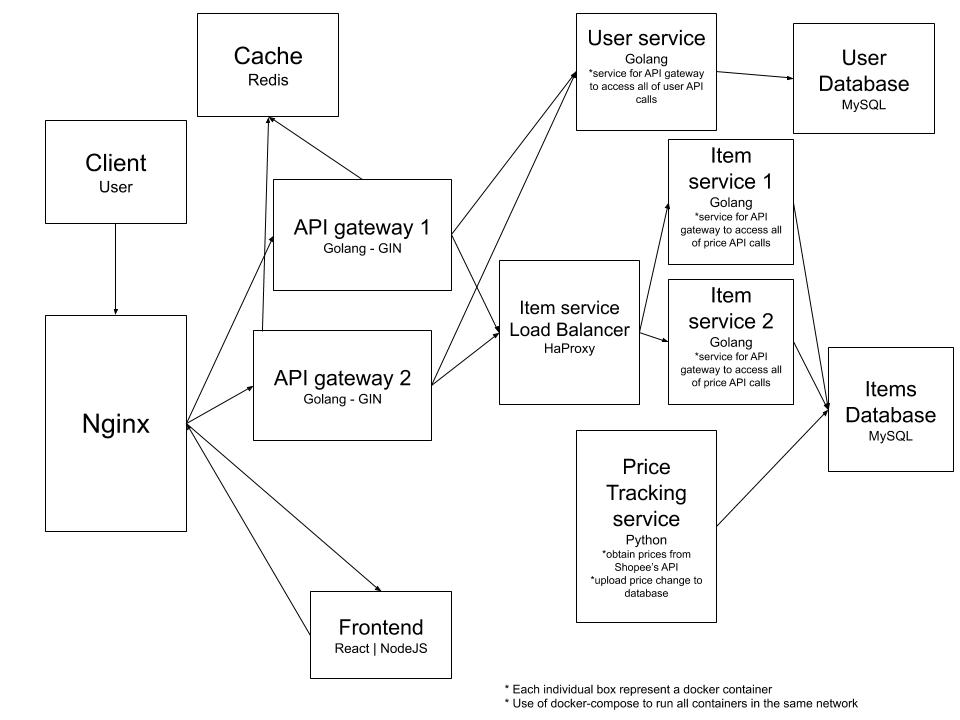
Next, I developed each service all seperated into their seperate docker containers using docker-compose. In total the application consist of 14 containers including load balancing and metrics tracking services. The services was built with Nginx as the gateway routing request to the api-gateway and the frontend and also load balancing for the api-gateway. Go-Gin was used for the api-gateway which is the access point to all APIs which then communicate with the various services based on the functionalities. There were 3 main services - user service, item service and price service. The user service was for all endpoints requiring user data developed in Go, the item service was for all endpoints requiring item data developed in python and the price service was for retrieving data and storing them in DB from Shopee's public APIs.
Stress testing was conducted to find the bottlenecks of the system and to try to increase the Queries-per-second (QPS) to as high as possible. Various optimisation on each service was made after each stress test such as adding load balancers for highly strained services such as the item-service anf the api-gateway and also to minimise connection time between services through connection pooling. Final QPS was at 500 for certain endpoints for when the system was ran locally on a MacBook Pro 16.
This task was done in my first 2 weeks in the internship. It was a challenging but fruitful 2 weeks as I learned alot of new technologies and learned various ways to design software so that it could be more optimised for a more scaled usage. It was my first time exposed to metrics tracking software such as Prometheus and Grafana to track various metrics to find bottlenecks in the application to be optimised via stress testing. It was also my first time using the RPC communication protocol for inter-service communication and it got me very interested in this way of communication due to it being lighter weight than REST. Overall it thought me how to design and develop software keeping optimisation and scalability in mind while still ensuring the functionalities were met. This project led me to be very interested in the micro-service architecture and to research more about it for future projects.
This task was given to me to migrate a current production feature from the current implementation in Python-Django to the new BFF Architecture using Golang. The reason for the migration is due to the increase in performance of the service by up to 6x from the migration and also to slowly migrate features out of the old architecture to the new BFF one for better maintainability and separation of logic. I was tasked to re-design the feature to fit the BFF architecture and to implement the feature in the new service with Golang. The API endpoint for this service is a high traffic service of a peak QPS of up to 40K due to it being a request that the homepage of Shopee website calls.
At the end of the migration, I conducted stress test on both endpoints to determine the difference in performance. I also did profiling during the stress test to further optimise the code to achieve the best QPS for the least amount of container instances. My newly developed endpoint in Golang managed to achieve a QPS that was 6.3x more than the old endpoint in Python when taking into consideration all things constant such as the amount of CPU used and the number of container instances available.
This task thought me the importance of consistency and availabilty of a software system as the migration of this feature gave me the opportunity to look into Shopee's architecture and I had to design the migrated feature service to be able to be always available and to always provide consistent response. Through this task, I had to properly design my technical documentation and test cases to ensure that the feature would be well documented and well tested to be put into the production environment. It was a good learning experience to put all this consideration into top priority when designing the system and I learned alot from it. It was also my first time being exposed to the BFF Architecture and it exposed me to the benefits of such a design pattern.
It was also a very good experience to be able to perform a stress test on my API endpoint to judge the performance of it. I also performed serveral rounds of profiling on the services to discover various bottlenecks and further optimise the service. The results turned out to be a massive improvement and it thought me the importance of doing performance test and profiling to not only compare results, but also gauge the hardware resources needed to support the live endpoint and the business use case. Profiling could also help you keep track of badly written code during development, and point out small optimisations which could in the end increase CPU optimisation by a huge sum.
This task was given to me to create an internal release tool on the command line interface to replace the current release tool so that proper documentation could be documented on each release for easy access to all developers. The idea of the project was to save developers time by ensuring proper documentation is noted down while not requiring each developer to manually maintain the page for the software library
This task was given to improve on the current compare tool that was used to compare the API response of the old architecture with the new one after migration to ensure that traffic is being served with the correct response. The idea was to use the library of GoReplay to replay the traffic coming into the original service to the new service and then writing a middleware to compare the response data of both services and ensure they were equal.


Software Engineer Intern


CZ4034 - Information Retrieval Project
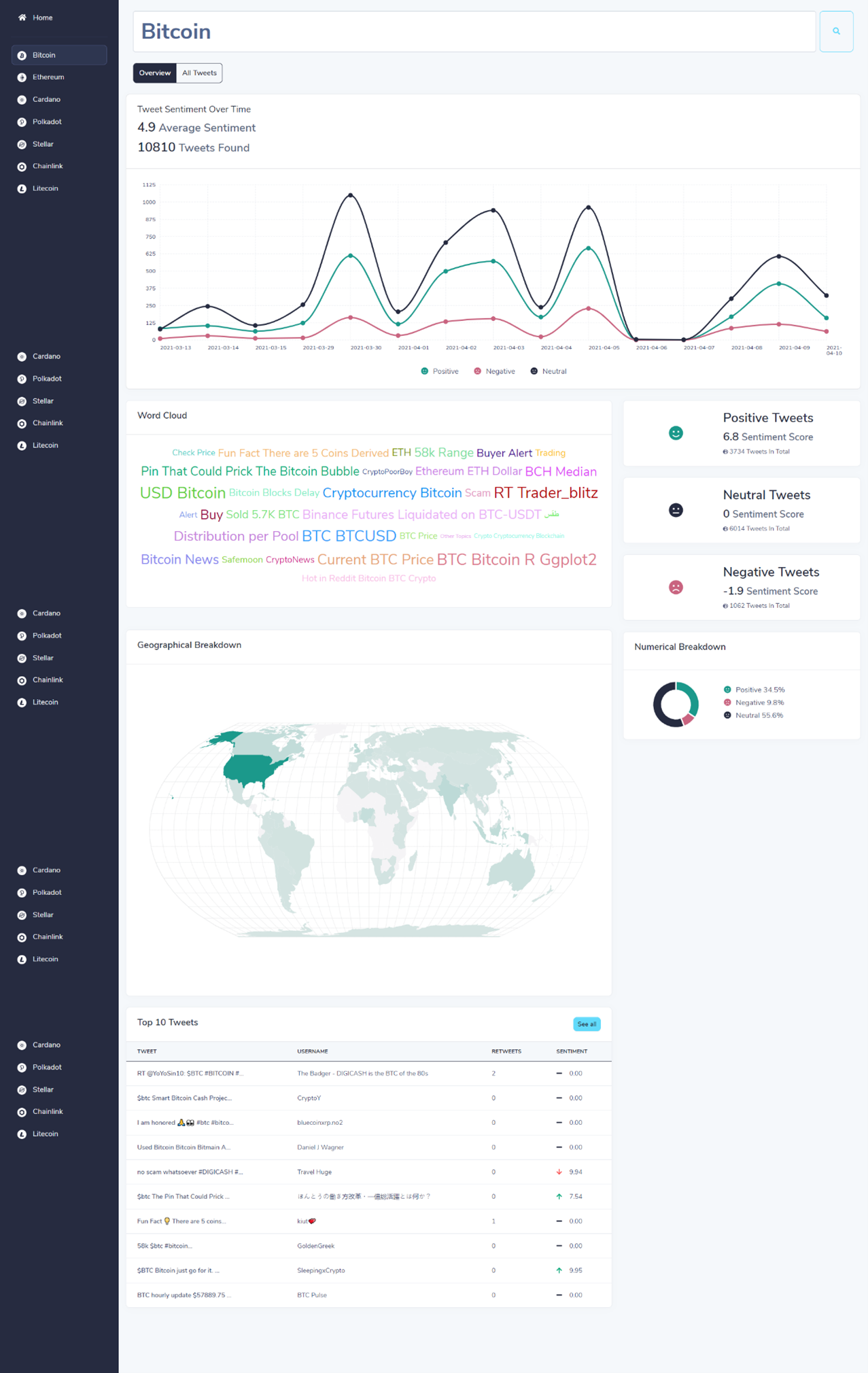
Python, Solr, Lucene, Jetty, React
Personal Project
Golang, React, AWS, MySQL
Renaissance Capstone Project

Azure Cloud, C#, SQL Server, Python, Azure IoT Edge, ReactJS
CZ4153 - Blockchain Project (Decentralized Application)
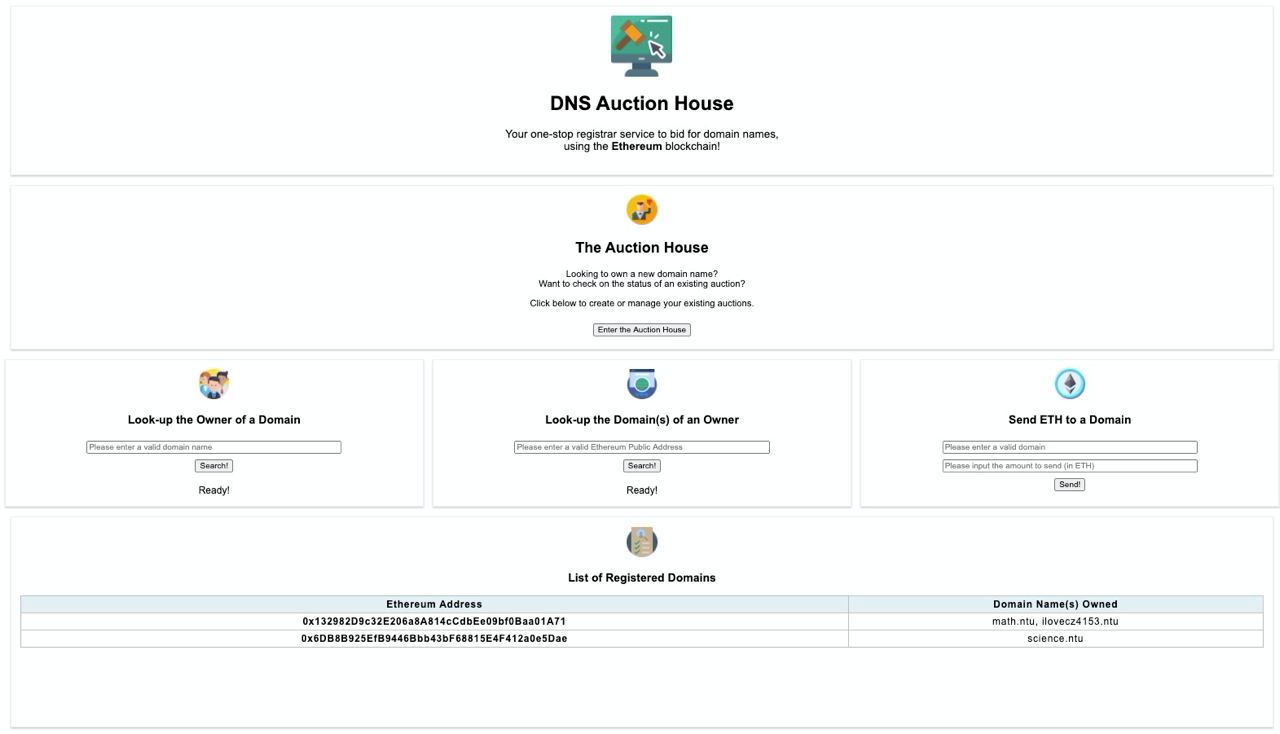
Solidity, Ethereum, ReactJS
Competition
Python, Flask
Personal Project
ReactJS for frontend, Firebase for database
The idea came about when I was travelling South America and I was scammed by a tour company when booking a 4D3N camping-hiking tour. I felt that the process of booking tours with smaller tour companies were really hard especially for tour companies that did not have online presence and hence it was hard to verify prices as well as verify validity of the company. Hence I decided to use technology to solve the problem via developing an aggregator website that would allow small tour agencies to have an online presence and hence give travellers more infomration when they travel and do adventures like this.
This was a project that I really wanted to do as I really loved travelling and wanted to find a way I could use my professional skill of software development to solve a problem regarding my personal travel experiences. I enjoyed developing the platform and would like to expand the business use case of it if possible.
Personal Project
Android for frontend, Firebase for database, Firebase ML Kit for Computer Vision
It was a personal project done during one of the recess weeks during my university semester. The idea came about when I realised that the process of logging vehicles entering private compounds were rather inefficient. Security guards either did not fully took down vehicle particulars and let vehicles into the compound to help speed up the process or took too long to take down particulars of each vehicle and result in long queues to enter the compound. I decided to come up with a personal project using technology to help speed up the process. The idea was to use Computer Vision through a mobile application to register a vehicle number plate just by holding the mobile phone camera facing the car. Using OCR technology from Google's Firebase ML kit, the car license plate will be registered to the system and stored in the database for logging purposes, hence speeding up the security check-in process.
The project was done solely as a side project to try to solve a problem I felt was an issue with technology. It turned out to be a rather fun project where I was exposed to how OCR works and how it can be used with mobile applications to essentially provide computer vision for applications that required quick processing yet with the constrain of a device that was readily available - mobile phone.
Singapore Airlines AppChallenge 2018

Flutter & Dart for frontend, Firebase for database, IBM Watsons for Chatbot
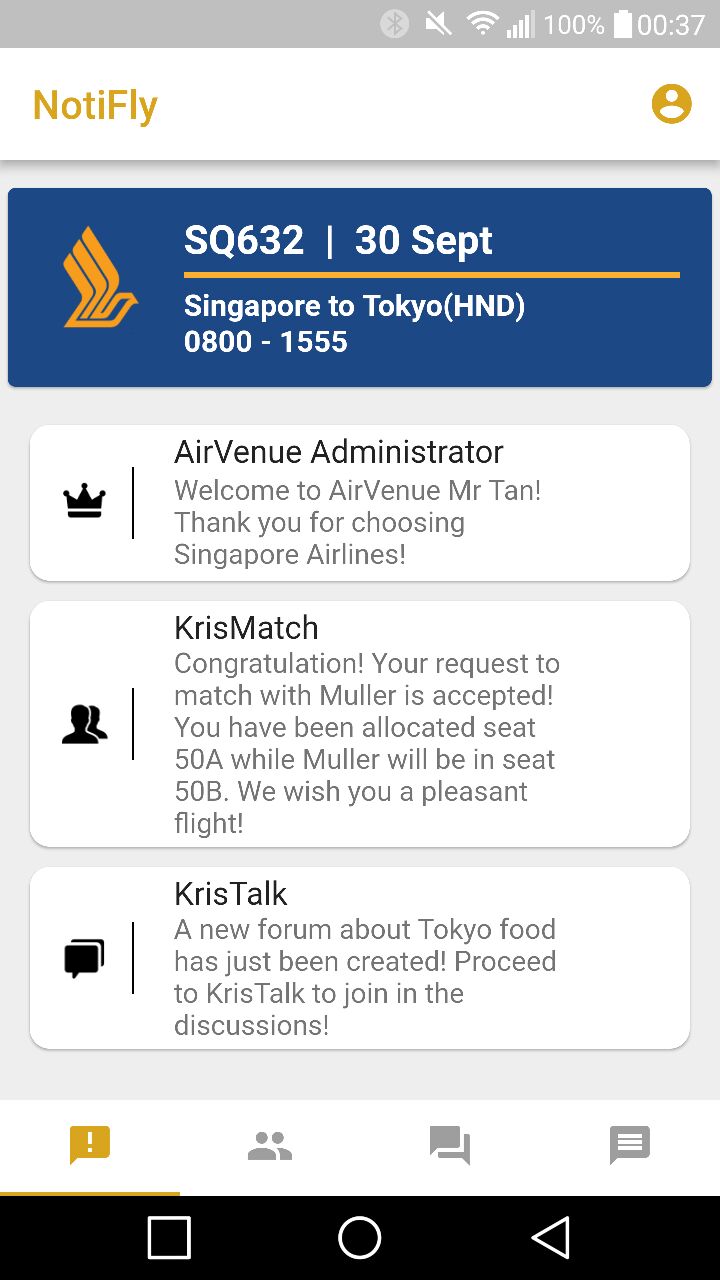
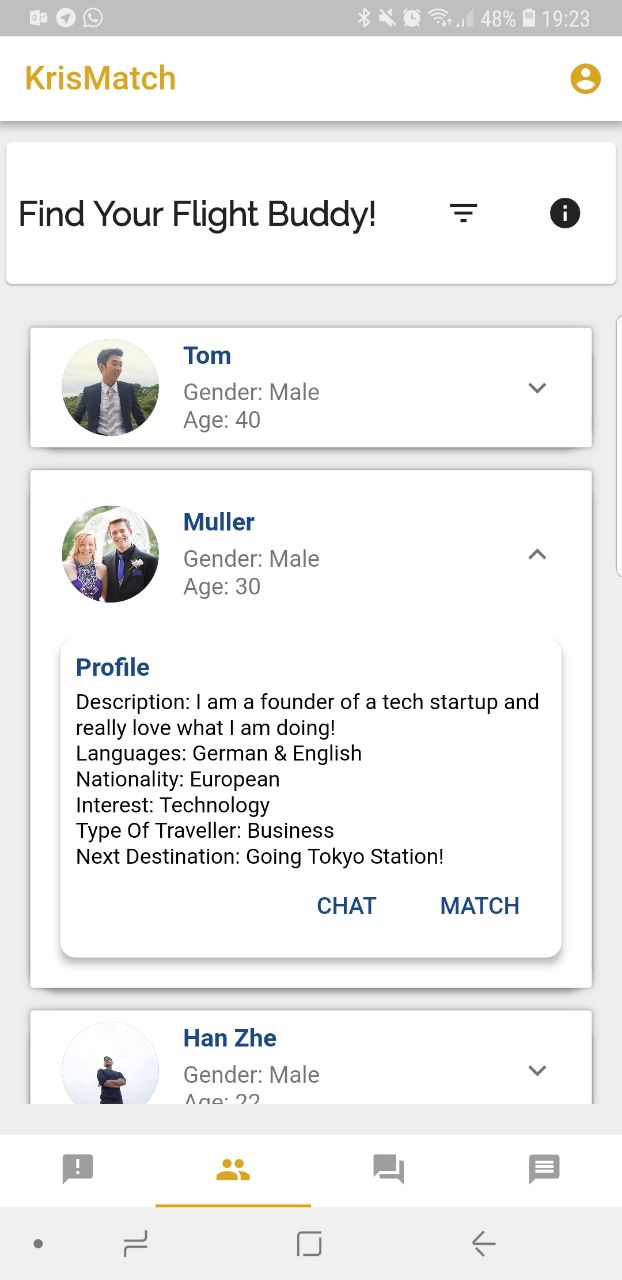
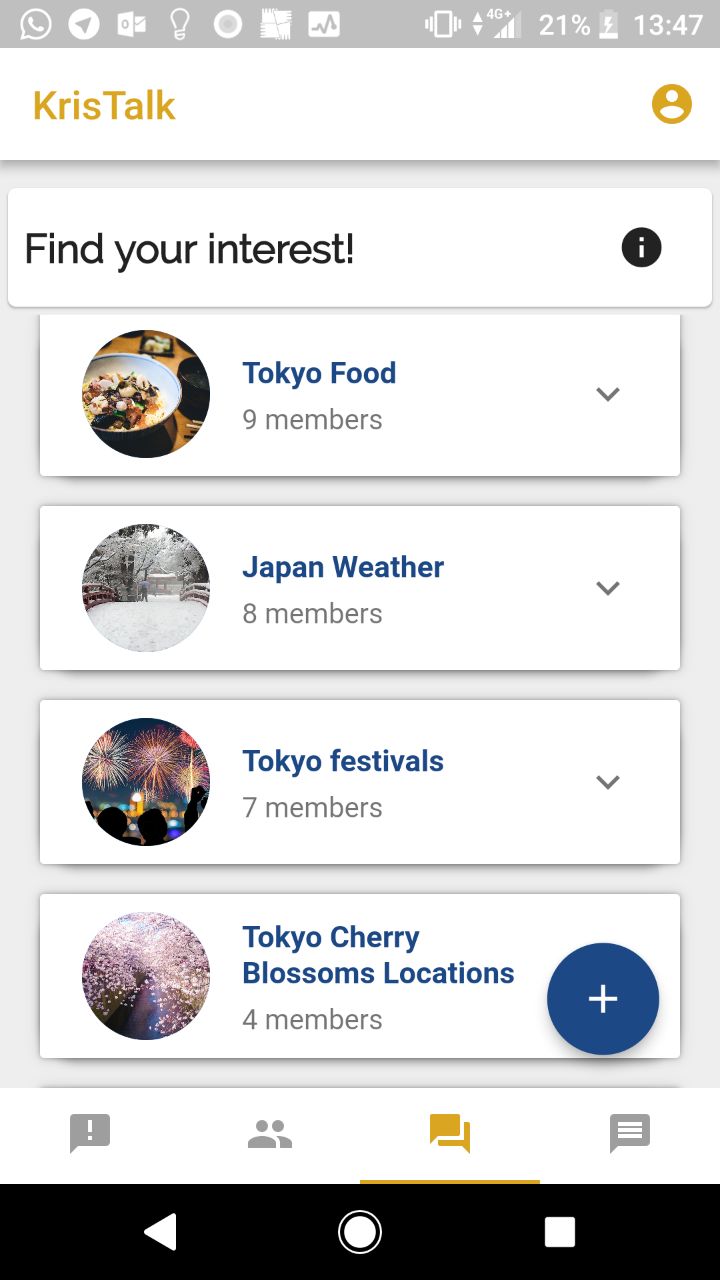
AirVenue is an application for the SIA AppChallenge 2018 solving the problem statement of increasing user engagement and aims to be an integrated platform for social connectivity that value-adds the current SingaporeAir app. It is a one-stop avenue for passenger-passenger as well as passenger-SIA connectivity, that aims to revolutionize the air travel experience by making it a social one. AirVenue consist of 4 main features namely Notifly, KrisMatch, KrisTalk and EverBot.
An announcement page that serves as a crucial bridge of information between SIA and passengers.
Matching system that allows flyers to find passengers with similar interests and potentially arrange a seat together on their flight.
An online forum platform within the flight for passengers to share their personal travel experiences with one another onboard the flight.
Chat bot that allows users to ask pre-flight questions and to request for inflight services such as availabilty of toilets and drink service
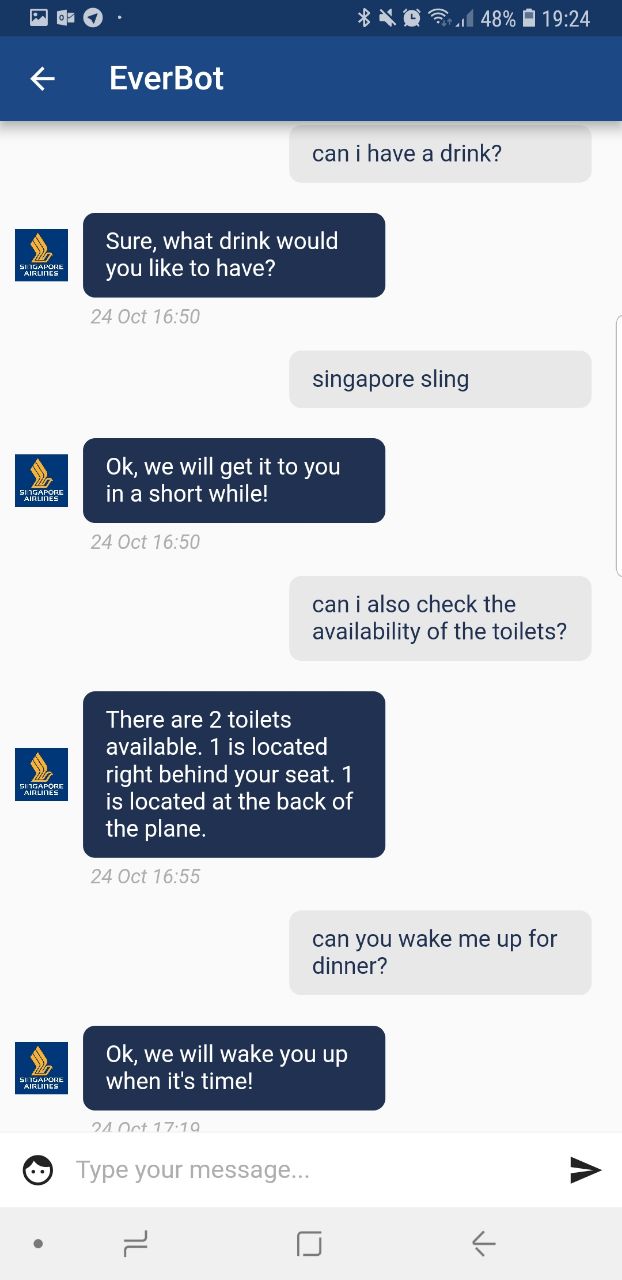
Dealing with the time constrain to develop the application as well as the business pitch for the submission dates. As we started off with little knowledge of app development or flutter, we had difficulty developing the application at the early stages. However we managed to learn on the task and managed to develop the application on time.
Getting into the Grand Finals of the competition and being able to pitch our idea and application to the executive members of Singapore Airlines.
Working in a team for a software development project and being able to use technology to help businesses solve problems.
This was the first major competition I joined and it was a unique experience. It allowed me to view technology as a tool to solve many business challenges in innovative ways. Getting into the finals was a great achievement for me and was an eye-opener as well where we got to have mentors from Singapore Airlines software team to guide us about the business challenges they face and how we can better cater our application to their business needs.
Shoppe National Data Science Challenge 2019

Python, Pandas for data visualisation and data pre-processing, Keras for building the models
Shoppe National Data Science Challenge 2019 was a data science challenge that required participants in teams of 4 to categorise products on Shoppe's site into different product categories using the product's name as well as image. For this particular challenge my team participated in, we were tasked to categorise more than 700K entries into 58 different sub-categories which are splitted across 3 major categories namely beauty, fashion and mobile. Click here to view more information of the competition.
We analysed the train data and generated the top words in each category. We also trained a simple neural network to generate confusion matrix for deeper analysis into which categories are often mixed up with one another. Therefore, we performed text cleaning on both the train set and test set. The text cleaning methods that we utilised are: Improve consistency of important words of high frequency by replacing certain terms such as “lipstick” to “lip stick” and “i phone” to “iphone”, translation of the Bahasa Indonesian word to English using the Google Translation API, removal of keywords of a particular category from other categories based on the confusion matrix and removal of stopwords, single characters, numbers.
We started by using only one single model that takes the inputs from all categories. However, the results were not great. This is because the data from each category have very different features. In our case, using the Bag Of Words method, each big category will have different frequently-used words. When passing the training data to the neural network, it is difficult for the network to identify these features or frequently-used words. With that in mind, we decided to split the data into each big category(fashion, beauty, mobile) before fitting them into models for training. That way, each model responsible for each big category can better differentiate features of each small category (Crop Top, Wedding Dress etc.)
We have experimented on several methods to vectorise the texts, such as word2vec, TF-IDF and Bag Of Words. After experimentation, we finalised on the Bag Of Words approach. It works by counting the occurrences of all unique terms in all the titles. With a specified maximum words of 1000, we extracted the 1000 top occurring words and performed vectorization of the titles using multi-hot encoding.
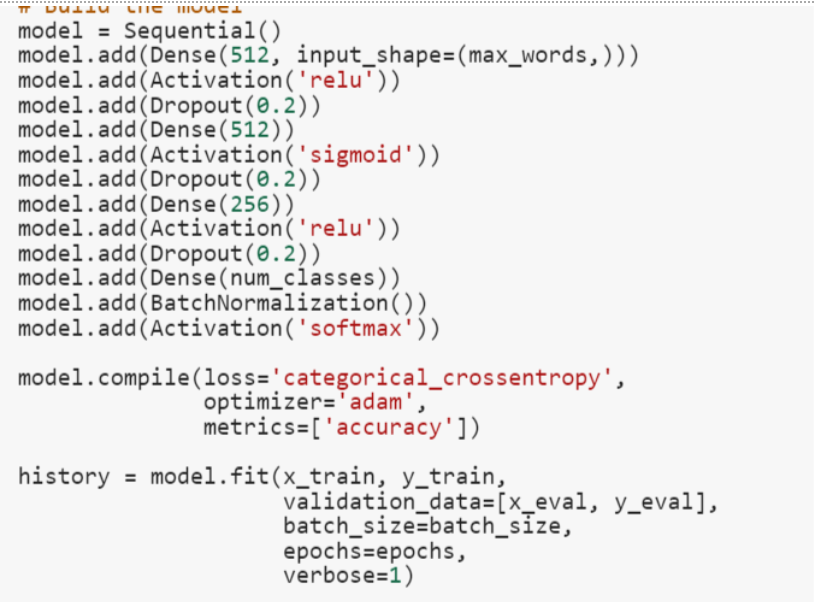
For the training of text dataset(title of items), we created a neural network. We used a sequential model that passes a given input through a series of dense layers. We have chosen to use the ‘relu’ activation function because it is better able to introduce non-linearity to the nodes in the neural network. The BatchNormalization layer near the end of the model prevents allows the model to train faster due to higher learning rates. Moreover, by normalizing the data before passing it into an activation function, it regulates the values entering the function, helping us to achieve a more accurate results. During the training process, we plotted graphs and used Tensorboard to help visualize our data. We optimised the training process for each model by doing the following: Splitting the data to training set and validation set, identifying the optimal number of epochs that give us the lowest validation loss, plotting the confusion matrix and identifying the categories that are easily wrongly-classified and identifying common words and account for their variations (line dress, linedress, a line dress etc.)
After finalising on the model architecture, we further fine-tuned the model by experimenting with several hyperparameters such as Number of layers, Number of nodes in each layers, Dropout ratio, Optimisers, Activation function, Batch sizes and Number of epochs With this, we generated several models with different hyperparameters for each big category (Beauty, Fashion, Mobile) to be used for ensemble learning.
We used the models generated from hyperparameters tuning for ensemble learning to make some final improvements. We adopted the stacking (meta ensembling) technique to combine information from the models we generated. The stacked model will be able to emphasise on the areas where each base model performed better while at the same time disregarding those areas where it underperformed.
After analysing the text data and the frequencies of each word in each categories, we developed a string matching algorithm. With this approach, we first created a dictionary of keywords for each category. There are three possible cases with this approach: 1) Title contains keywords from none of the categories. For this case, we passed the text data through our trained neural network to perform prediction 2) Title contains keywords from only one category. Final prediction would be the category that the keyword(s) is in. 3) Title contains keywords from more than one category. Similar to the first case, the data is then fed into the neural network for prediction However, we saw no improvement in this approach compared to the pure neural network approach.
Getting the top 10% in the leaderboard on kaggle (35th out of 360 teams).
I learned how to analyse data using pandas, do data pre-processing, designing different neural network models as well as tuning hyperparameters to achieve optimal accuracy.
This was the first major competition in the data science field I joined and it was a unique experience. It allowed me to learn the basics of data science and find out how powerful classification models can be. Prior to joining the competition, I had no experience in data science at all and this competition made me more interested in data science and how powerful data is when applied to various real world problems.
NISTH Ideas Challenge 2019

NTU Institute of Science and Technology for Humanity (NISTH) is a new initiative started by Nanyang Technological University (NTU) to act as a platform aiming to spearhead research, connect all stakeholders in sustained dialogue and focus public attention to the impact of technology on society. Together with the grand opening ceremony of NISTH, NISTH held a competition which aims to involve the entire campus community in mapping the fundamental issues and principles that would help guide the development of Artificial Intelligence (AI) for the benefit of society and humanity. My team submited a research proposal to investigate how severity of scenarios affect human preferences towards rule-based and randomized automated decisions. Click here to view more information of the competition.
Click here to view our research proposal.
This competition made me more aware of the social impact technology has on society. It made me realise how as someone who is intending to venture in the field of technology to always pay attention to social problems that technology can bring and ensure that any advancement in technology should not result in any ethical issues. It was interesting to be part of such an amazing initiative and having the opportunity to listen to other insightful ideas and proposals on how AI can benefit society and humanity.



Article: NISTH Official Article
CZ2006 - Software Engineering Project
Flutter & Dart for frontend, Firebase for database, IBM Watsons for Chatbot, Google APIs for Maps.
IPPT Buddy is an application for my Software Engineering project and aims to act as a platform for NSMen to train for IPPT. NSMen can have a scheduler to meet their target result and find other NSMen to train with. It is a one-stop avenue for NSMen to train for IPPT and has the objective to help NSMen get their desired IPPT results. Users will log in and fill up their profile and targets for their next IPPT. IPPT Buddy consist of 3 main features namely Scheduler, MatchMe and Chats.
A scheduling page for the app to inform you of exercise you need to do to meet your target IPPT results. Users then tick off exercise when they are done for the system to re-generate another schedule for them.
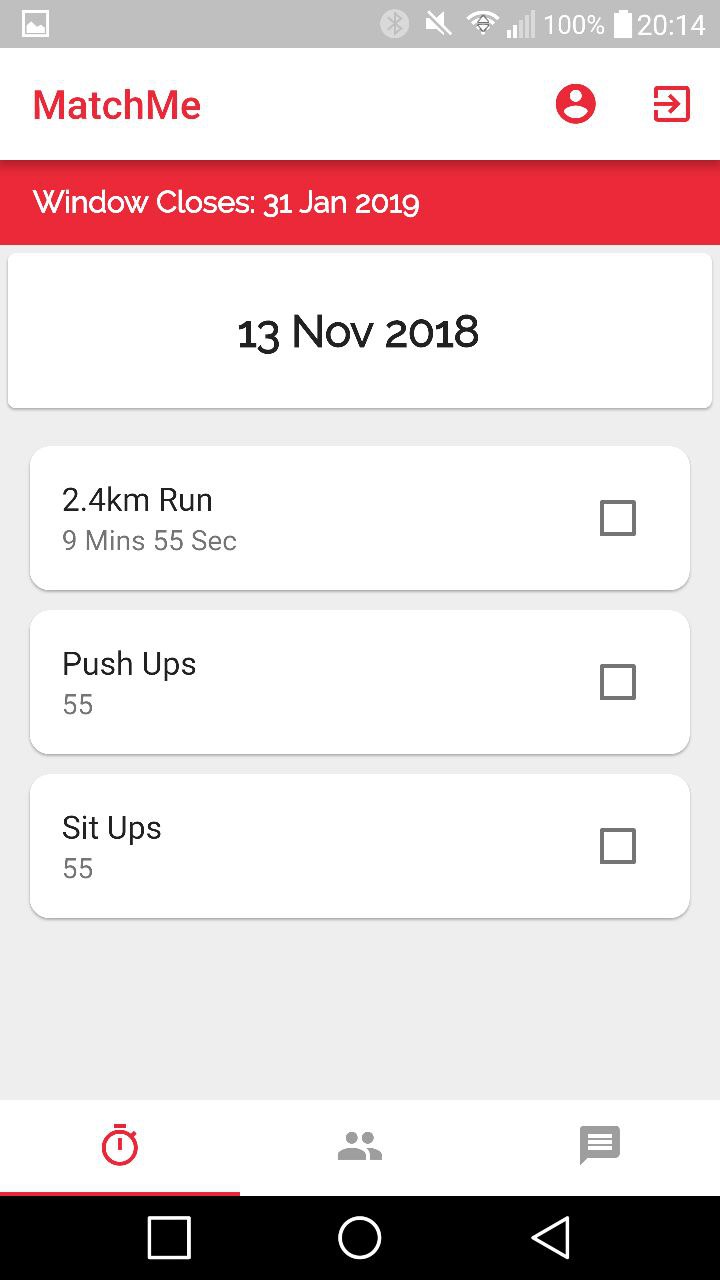
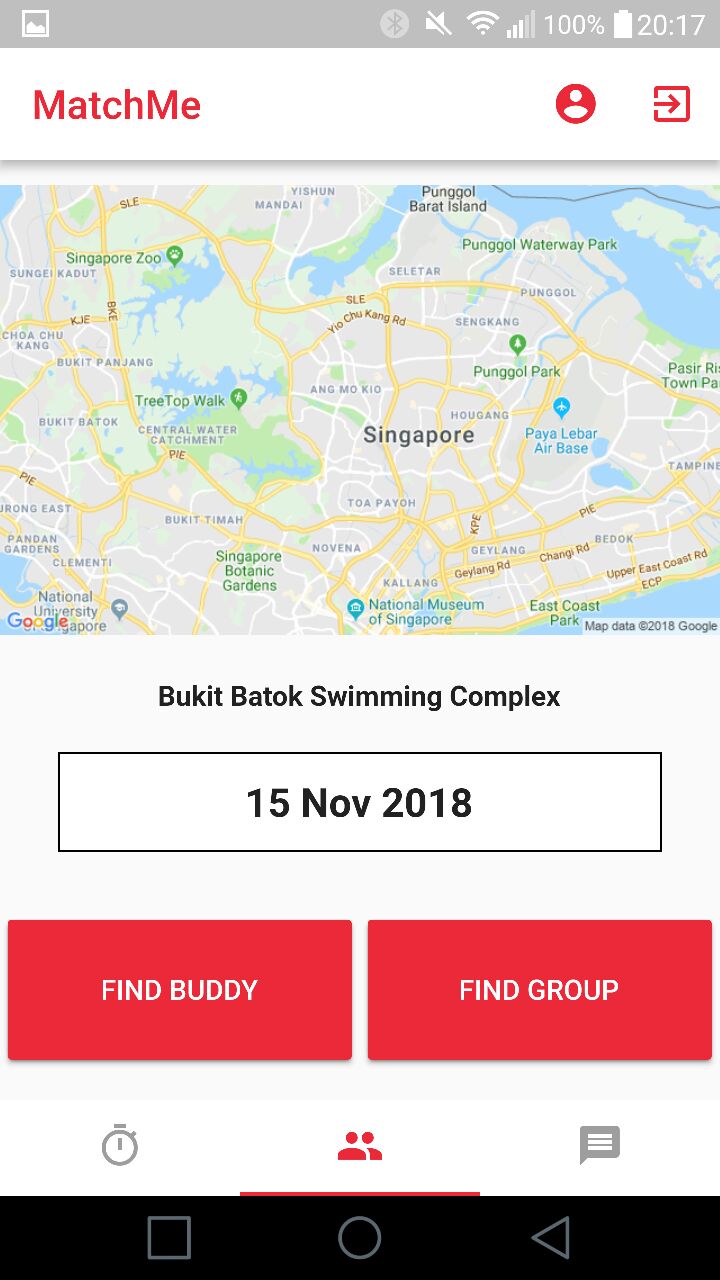
Matching system that allows users to find other users with similar fitness levels as well as their preferred training location to match and train together. Users can choose to find individuals to train with or groups.
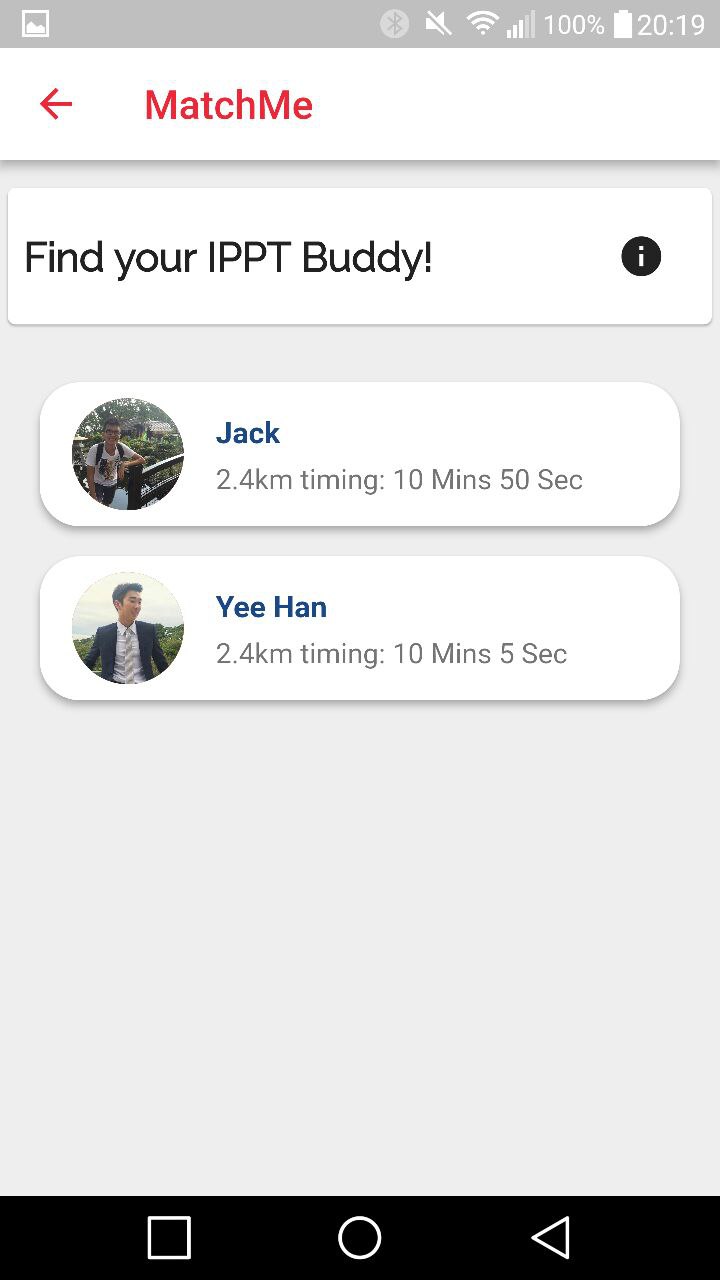
An online real-time chatting platform for users to connect and arrage for the meetup to train together.
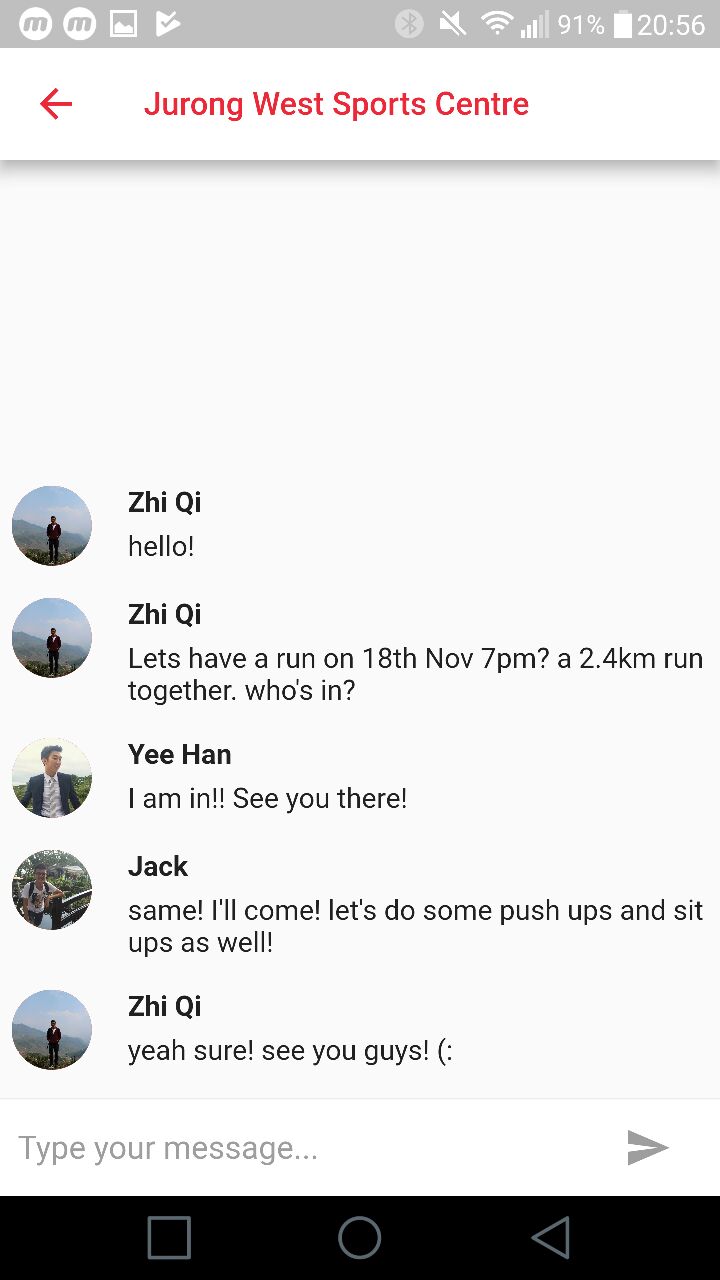
This project thought me the importance of having a Software Requirement Specification (SRS) to develop the application. It also highlighted the importance of comprehensive testing on applications.
Toshiba Retail Challenge 2018

Flutter & Dart for frontend, Firebase for database
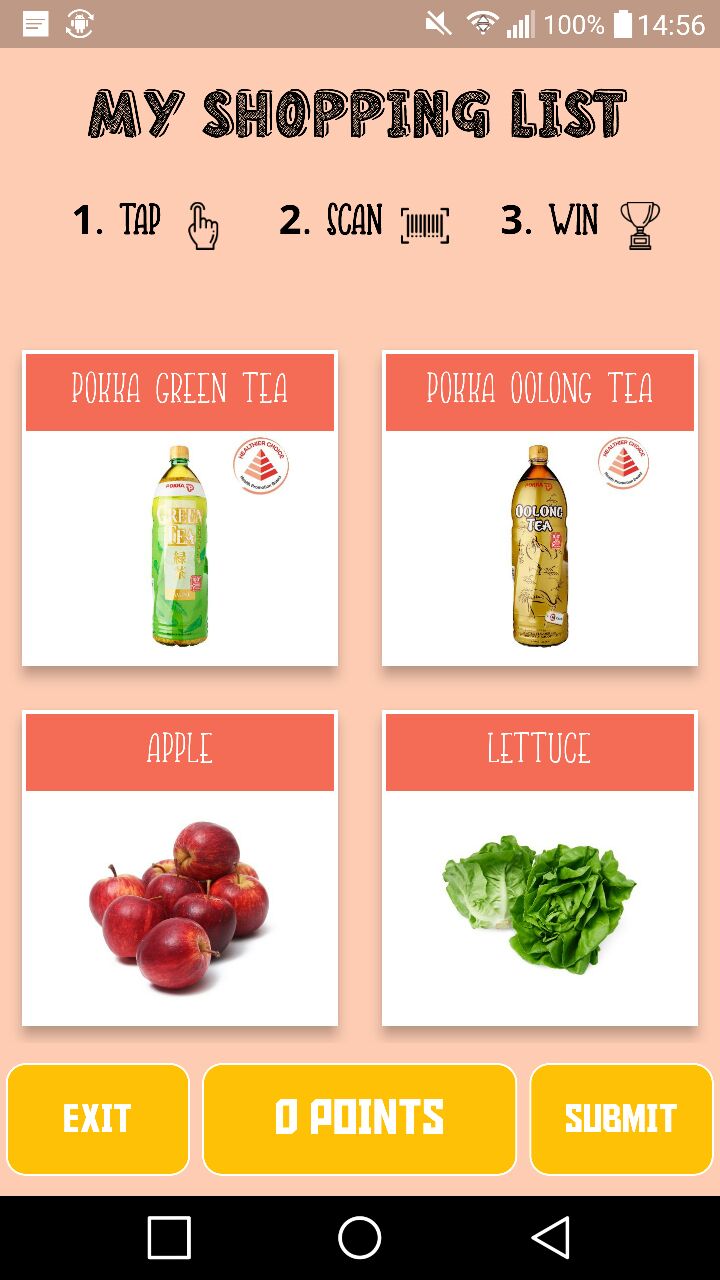
Jolley is an application for the Toshiba Retail Challenge 2018 solving the problem statement of bringing the fun back to shopping specifically at retail grocery outlets through a fun family centric game. It is a grocery shopping application where families can input items into their grocery list from a catalogue before shopping and then go to the grocery outlets where the family can play a game. The game requires the child of the family to go about the supermarket to find the specific items the parents have selected in their list and compeleting missions by scanning the barcodes of the items. Trivial questions will also be prompted to the child about the item for the parent to interact with the child.
Grocery list that is integrates with JolBook and JolPlay. Users can add to the list from a catalogue.
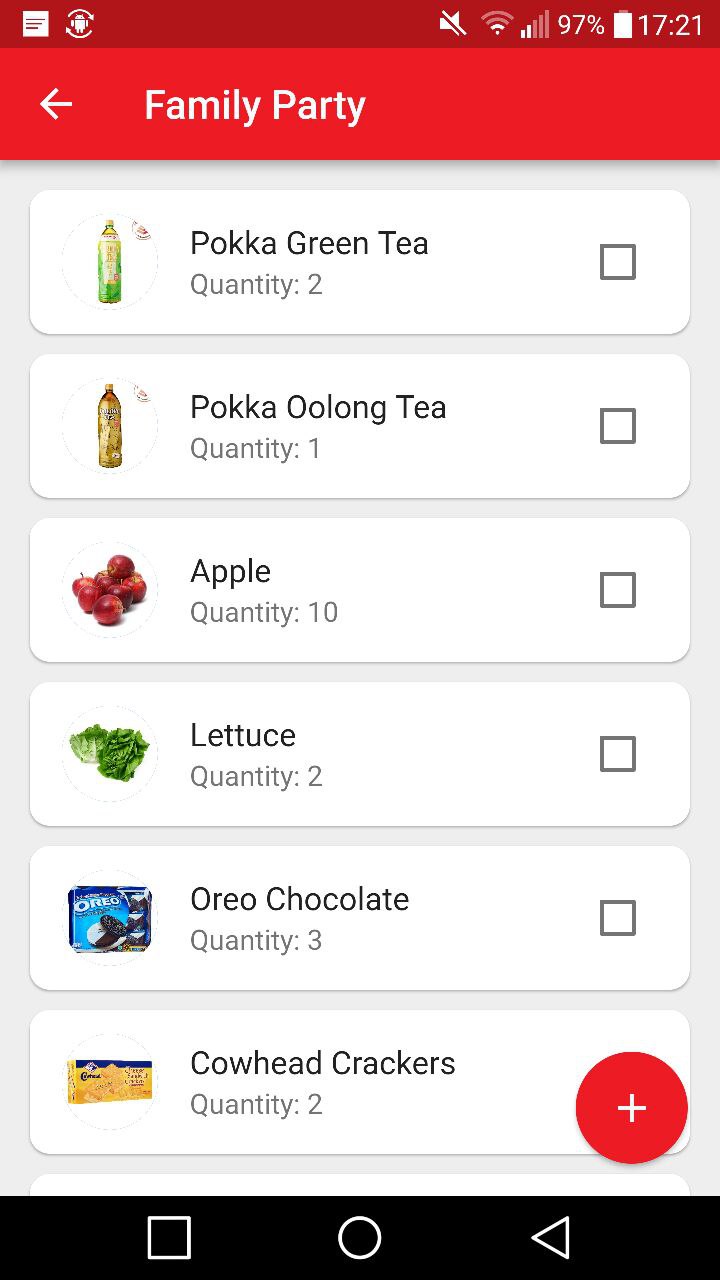
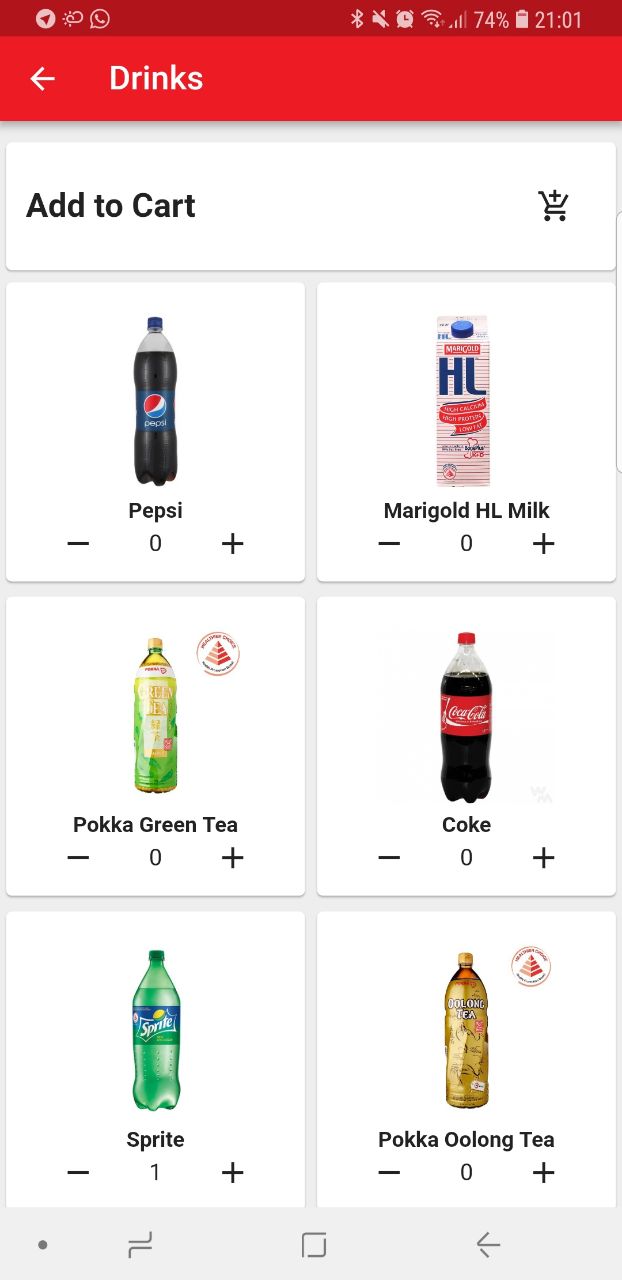
Exclusive recipes that bring family together to cook. Families can scan QR codes at grocery outlets for exclusive receipes where the items would be added to JolList.
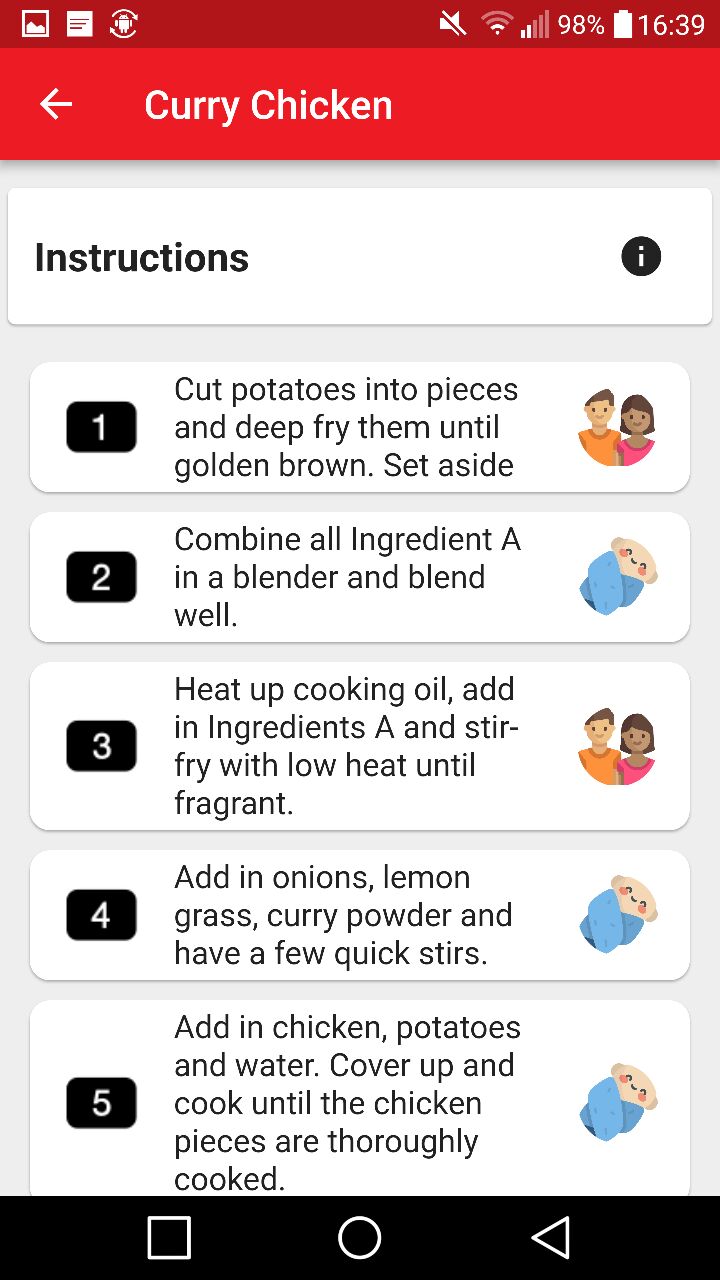
Interactive game that allows kids to have fun in grocery retail stores. The game brings kids on a treasure hunt around the store to find the groceries in JolList to complete their parents shopping list. Kids scan the barcode of the items and answer questions about the item to gain points.
It was a fun experience being able to pitch our idea to the executive team of Toshiba Singapore in a booth style presentation. It was also interesting to be able to watch the other groups present their unique software ideas to benefit the retail scene.
HacknRoll 2019
Arduino Servo Cup and utensils OpenCV Raspberry Pi Python Neural networks
Having met several patients who previously sustained injuries from accidents and had to go through physiotherapy, we understand that the rehabilitation experience can be too mundane and be really demoralising for the patients.
We aim to help patients recovering from their injuries by incorporating the game element into the therapy/rehabilitation experience. We hope that by adopting gamification with Augmented Reality (AR) will help to make it a more interesting and fun way to help the patients get better.
We used Arduino and 2 servos to create the prototype robot. We also used aluminium foil that will be worn on the body to act as a controller for the robot by transmitting information through simple hand and leg motions. We further attached a Raspberry Pi to the robot for the user to get a peripheral vision of the robot through a monitor where augmented reality elements are incorporated using OpenCV.
Creating the prototype with the limited materials and time we had. Getting the different parts together for the prototype was also very challenging as we did not have the necessary items. As this is our first attempt at AR and OpenCV, we ran into some complications while setting up the software and introducing the AR element.
The hardest and most satisfying part was establishing the connection between the robot and the user - the transmission of information to the robot when the user moves and also the robot sending back visual information back to the user with augmented reality.
How to work with Arduino, Servos for the creating of a working prototype and using OpenCV and Machine Learning to deal with image recognition and creating AR.
It was a fun experience trying my hands on Augmented Reality and computer vision. Through the 24 hours hackathon, I was able to learn OpenCV and exposed myself to the world of AR. I really enjoyed myself working on this project.

Arm Rehab starting position

Arm Rehab ending position, connects motion to the robot's arm

Raising arm to control the robot's arm

Robot with RPi Camera attachment for AR gameplay

AR using opencv : overlay enemy with HP
Personal Project
Android for frontend, SQL for database
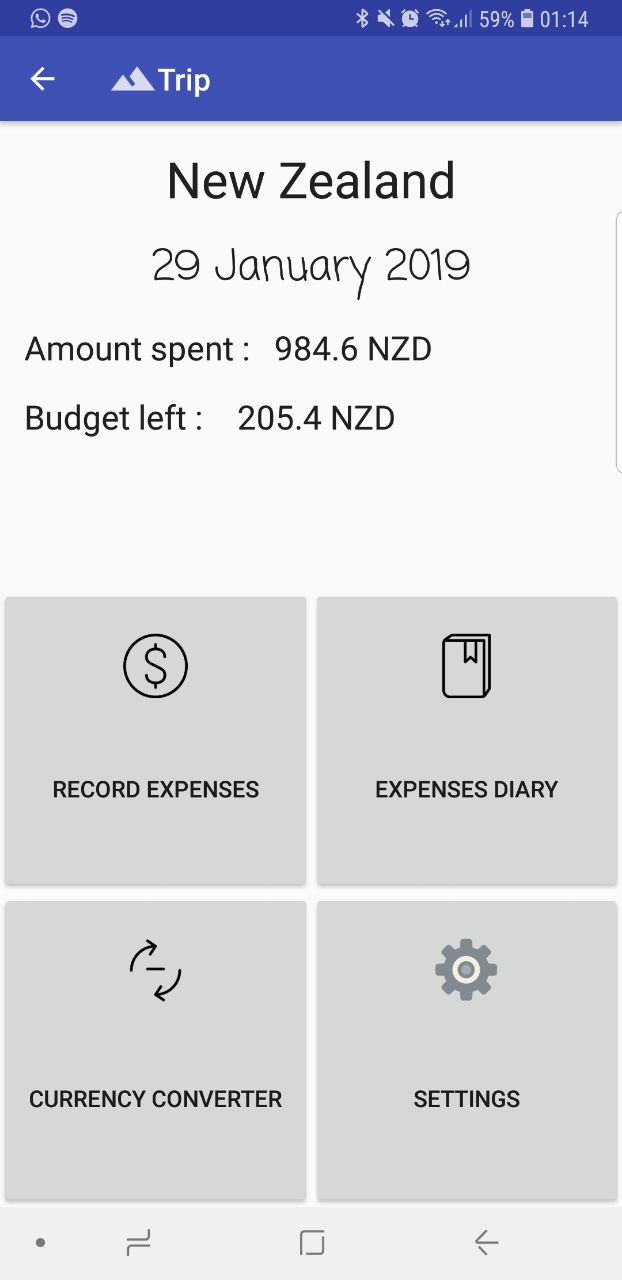
I love to travel but I always had a tight budget in all my trips. I also found it incovenient to always be converting currencies at google rates when the rates I changed at the money changers weren't the rates on google. I also wanted it to be able to act as a diary for my travels. So therefore I developed an android application to record expenses while having a diary entry for each expense and also having a currency converter at the rates I changed my money for.
Before each trip, you will initialise a budget for the trip as well as the rates at which you changed your currency at for the application to generate a trip page in the database. From there the list will keep track of your budget and inform you if you exceed it.
Record expenses and record a diary of the description of what the trasaction was like. You can view a list and remaining budget through a list view of all transactions.
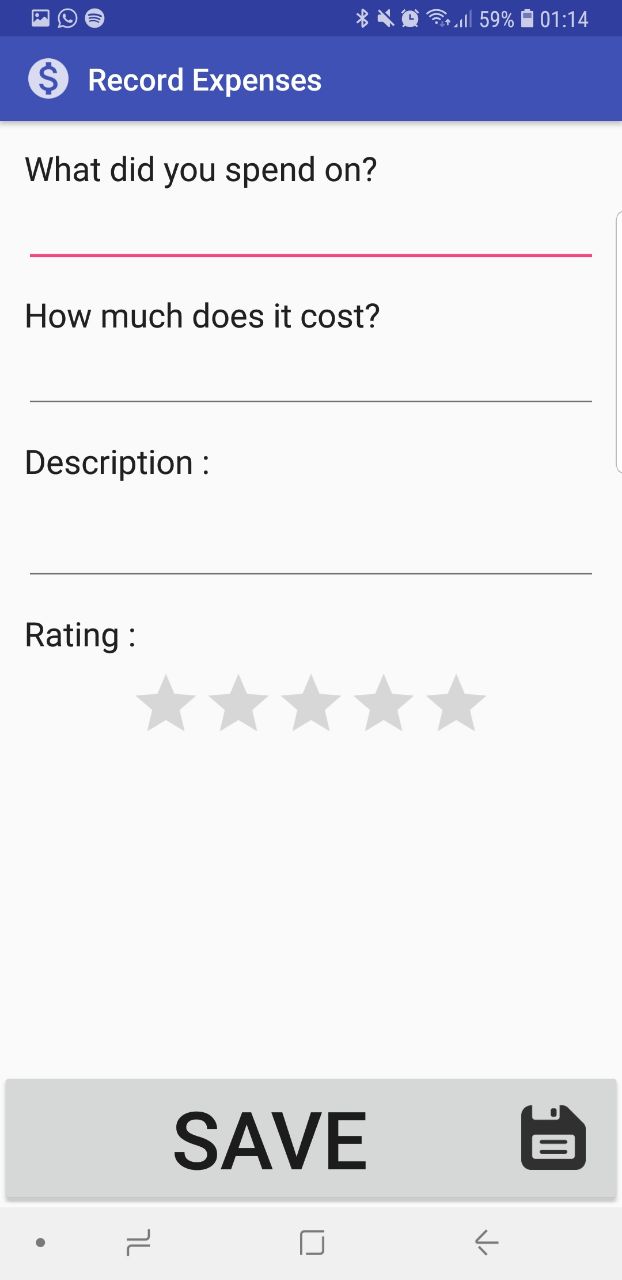
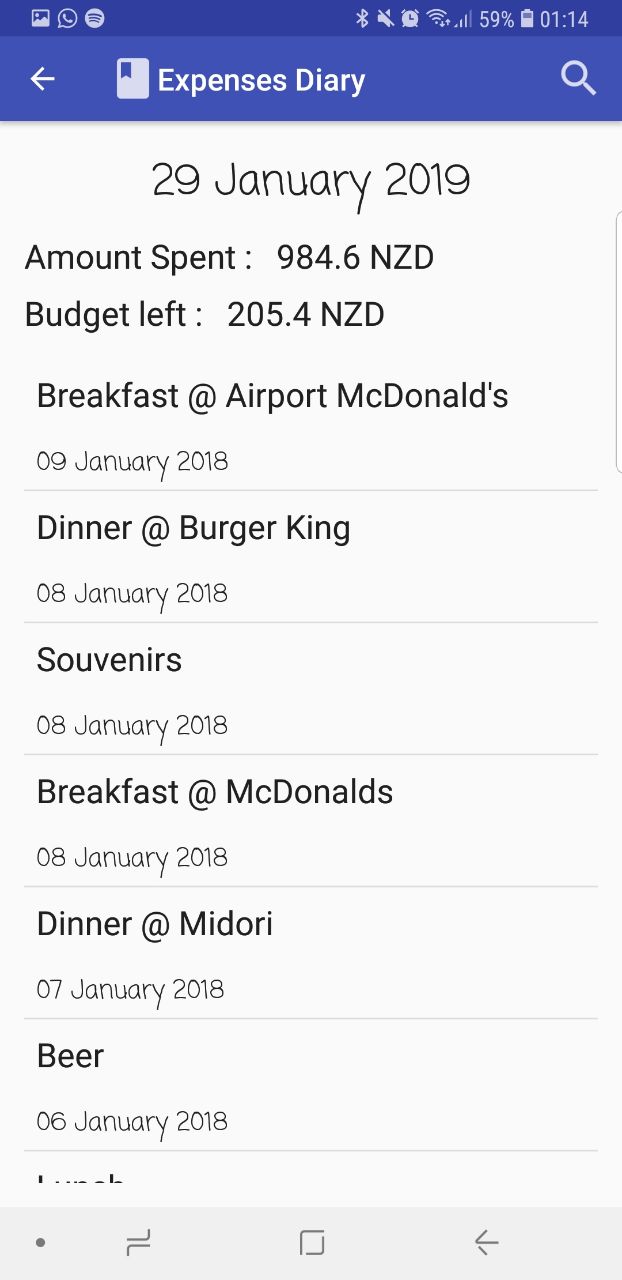
Convert currency to the rates that was changed at the money changer
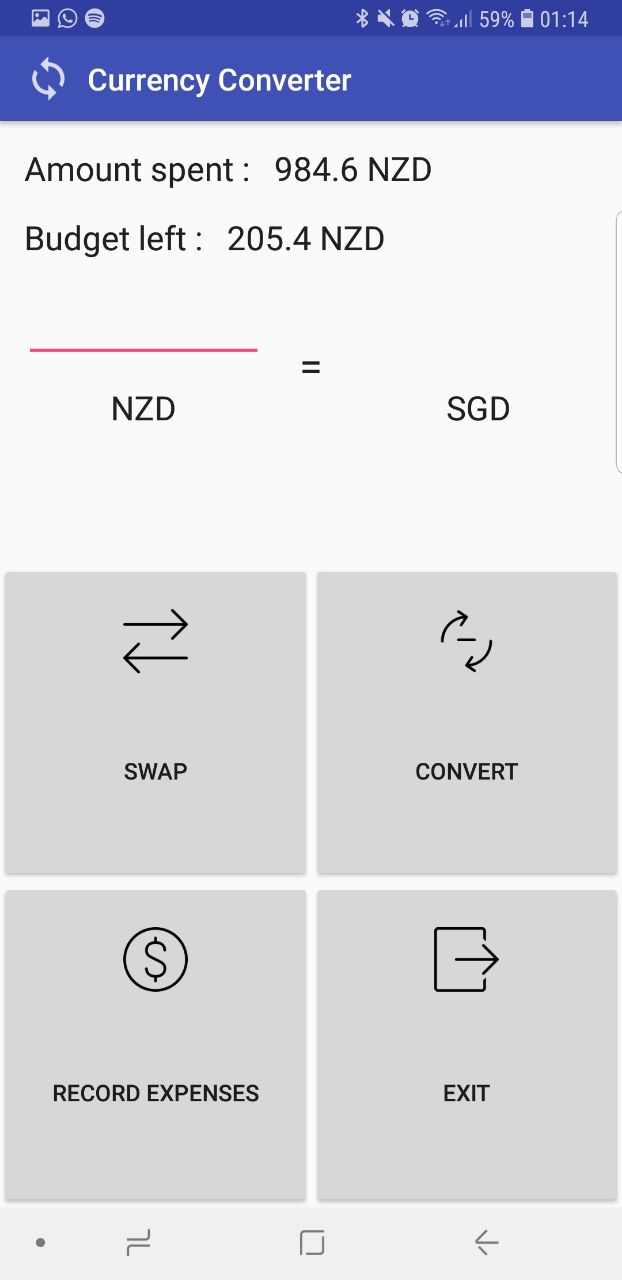
It was my first time developing a mobile application and was the project that got me interested in mobile development. I was fascinated at how I could create mobile applications to increase convenience to my day to day task. I really enjoyed the process of developing the application and it was what led me to be interested to join Computer Science as a specialisation.